












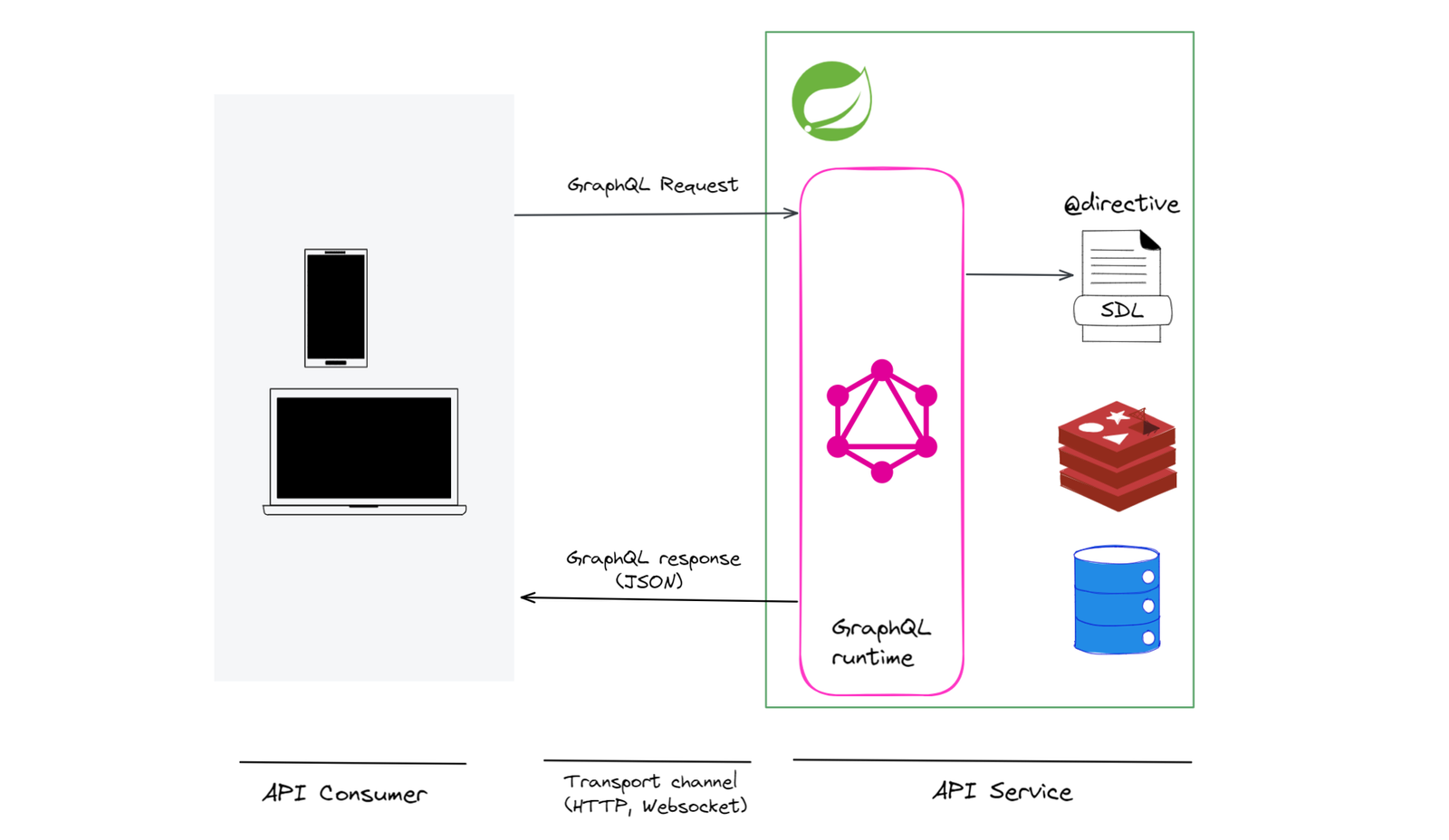










GraphQL promises to solve some major shortcomings associated with REST API, namely over-fetching and under-fetching. But, GraphQL is also prone to one problem, commonly known as N + 1 problem. In short, if the GraphQL service is not implemented correctly, it can cause significant latency in the API calls.
Not surprisingly, Spring for GraphQL provides an elegant solution to solve N + 1 problem.
So, what exactly is N + 1 problem in GraphQL?
What is the N + 1 problem?
Firstly, it’s not as dreaded as it sounds 😑. Secondly, it has nothing to do with Big O, used to describe the algorithm’s performance. Thirdly, the solution to the N + 1 problem is surprisingly straightforward.
But, before we discuss the solution, let’s understand the problem first.
Let’s try to understand this problem with one example.
Assuming, you have defined the following GraphQL Apis.
type Query {
books: [Book]
}
type Book {
id : ID
name : String
author: String
price: Float
ratings: [Rating]
}
type Rating {
id: ID
rating: Int
comment: String
user: String
}
And on the service side, it’s implemented as:
@QueryMapping
public Collection<Book> books() {
return bookCatalogService.getBooks();
}
@SchemaMapping
public List<Rating> ratings(Book book) {
return bookCatalogService.ratings(book);
}
In the above code, we have defined two Data Fetchers
books()for field books of the GraphQL object typeQuery.ratings(..)for field ratings of the typeBook.
The important point to note here is if you don’t specify a Data Fetcher for a field then the GraphQL assigns a default PropertyDataFetcher which, in turn, looks for the public XXX getXXX() method in the POJO object defined by the Type.
Therefore, in the above example, GraphQL resolves the field name from public String getName() method of the Book object.
Also, when the GraphQL service executes a query, it calls a Data Fetcher for every field.
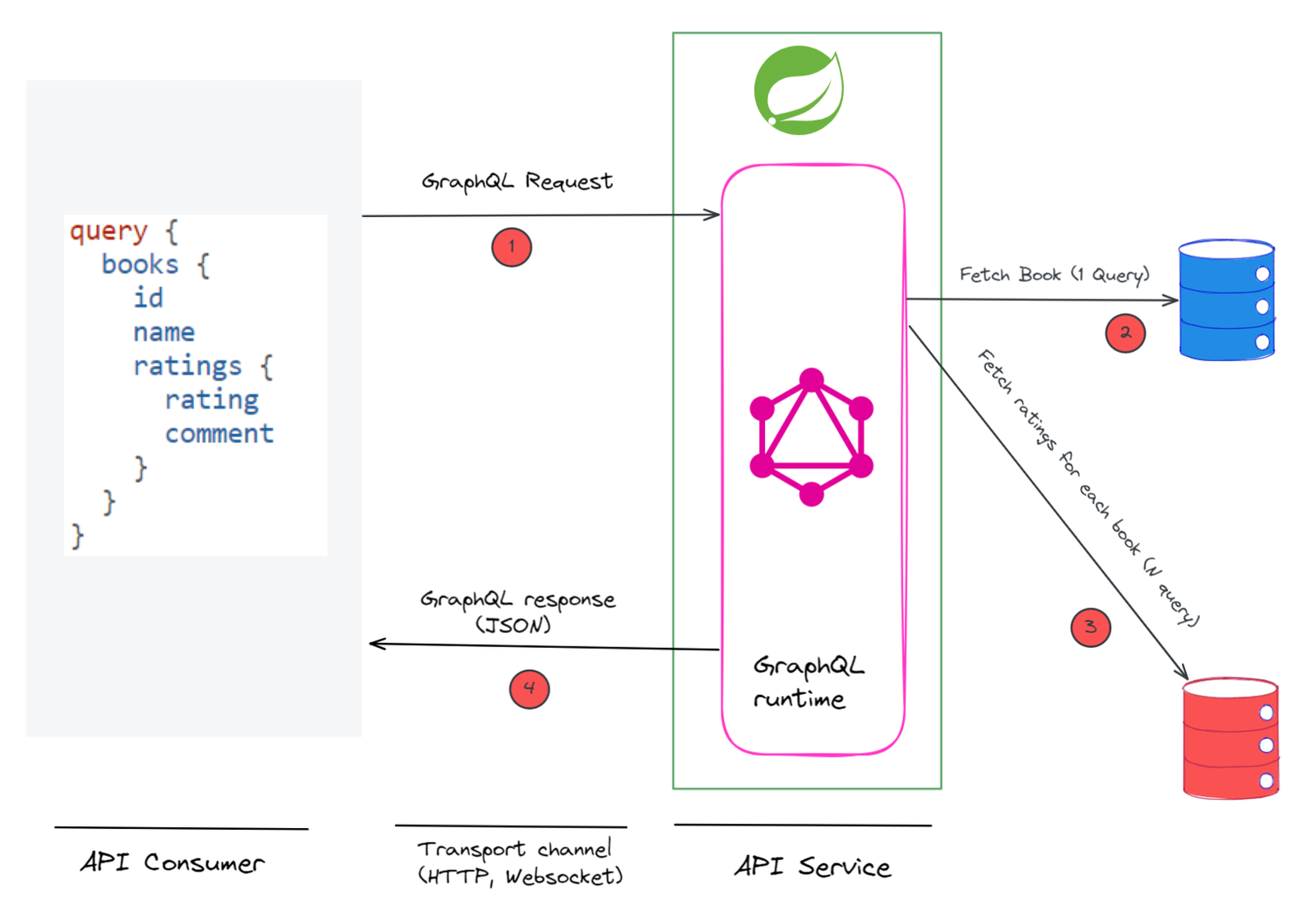
So, if a GraphQL client requests the following data,
query {
books {
id
name
ratings {
rating
comment
}
}
}
then the GraphQL runtime engine does the following.
- Parses the request and validates the request against the schema.
- Then it calls the
bookData Fetcher (handler methodbooks()) to fetch book information once. - And, then it calls the
ratingsData Fetcher for each book.
Now, it’s very much possible that Books and Ratings are stored in different databases, or books and ratings are different microservices altogether. In any case, this results in 1 + N network calls.
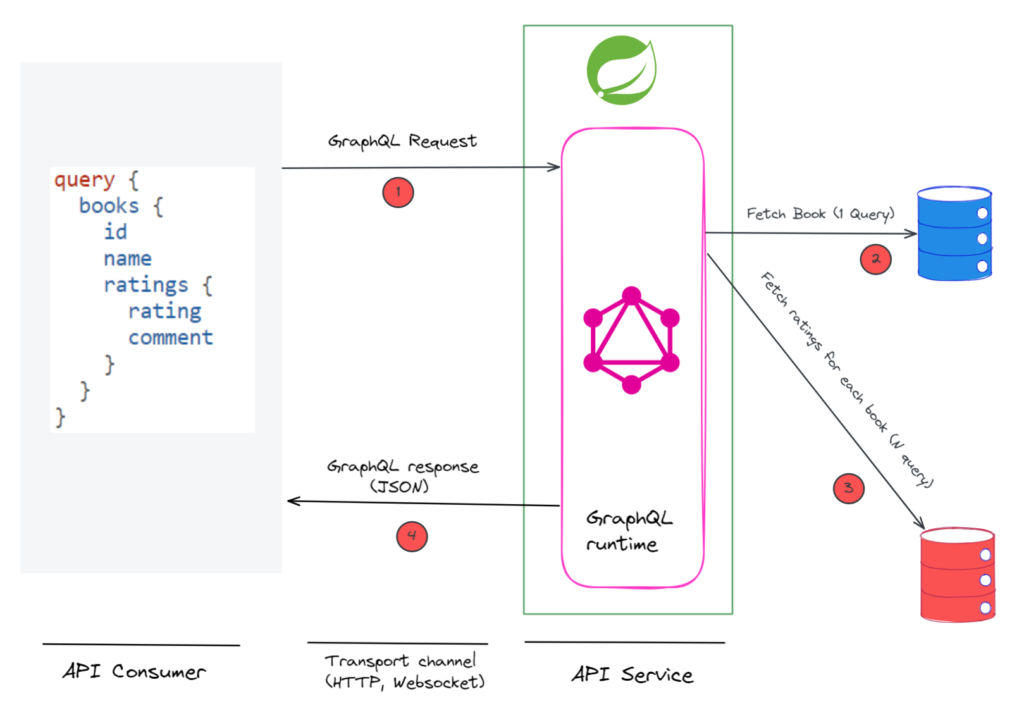
The n+1 problem means that the GraphQL server executes many unnecessary round trips to fetch nested data.
If you check the service log then you will see that rating Data Fetcher is called sequentially for each and every call to book.

How to solve N + 1 problem?
In Spring for GraphQL, you can solve this problem using @BatchMapping annotation.
You need to declare @BatchMapping annotation on a handler method that takes List<Book> and returns a Map containing Book and List<Rating> as:
@BatchMapping (field = "ratings", typeName = "Book")
public Map<Book, List<Rating>> ratings(List<Book> books) {
log.info("Fetching ratings for all books");
return ratingService.ratingsForBooks(books);
}In @Batchmapping, Spring batches the call to the
ratingData Fetcher.
You can also leave out the parameters field and typeName as the field name defaults to the method name, while the type name defaults to the simple class name of the input List element type.
@BatchMapping
public Map<Book, List<Rating>> ratings(List<Book> books) {
log.info("Fetching ratings for all books");
return ratingService.ratingsForBooks(books);
}
If you run the above query in GraphiQL at http://localhost:8080/graphiql?path=/graphql, you will see that the GraphQL engine batches the call to the ratings field.

Another approach to solve the ‘N + 1’ problem
There is another way to solve N+1 in Spring for GraphQL – using low-level GraphQL Java Data Loader API. A Data Loader is a utility class that allows batch loading of data identified by a set of unique keys. It’s a pure Java port of Facebook DataLoader.
This is how it works.
- Define a Data Loader that takes a set of unique keys and returns results.
- Register the Data Loader in the
DataLoaderRegistery. - Pass Data Loader to
@SchemaMappinghandler method.
A DataLoader defers loading by returning a future so it can be done in a batch. A DataLoader maintains a per request cache of loaded entities that can further improve performance.
Since BatchLoaderRegistry is available as a bean, you can inject that anywhere (in our case we have injected it in the Controller class for convenience).
batchLoaderRegistry
.forTypePair(Book.class, List.class)
.registerMappedBatchLoader(
(books, env) -> {
log.info("Calling loader for books {}", books);
Map bookListMap = ratingService.ratingsForBooks(List.copyOf(books));
return Mono.just(bookListMap);
});
And then define a handler method that takes Data Loader as an argument.
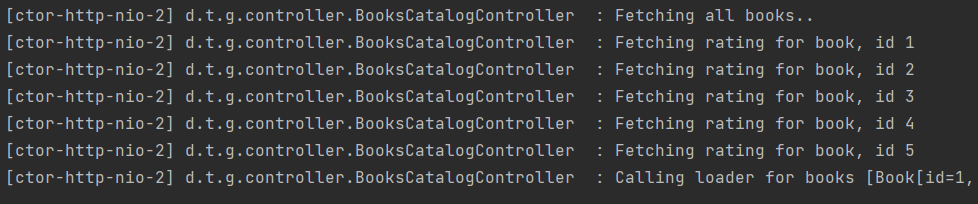
@SchemaMapping
public CompletableFuture<List<Rating>> ratings(Book book, DataLoader<Book, List<Rating>> loader) {
log.info("Fetching rating for book, id {}", book.id());
return loader.load(book);
}
If you run the above query in GraphiQL at http://localhost:8080/graphiql?path=/graphql, you will see that even though rating Data Fetcher is called for every book but GraphQL engine batches call to Data Loader as a single call.
Code example
The working code example of this article is listed on GitHub . To run the example, clone the repository, and import graphql-spring-batch as a project in your favourite IDE as a Gradle project.
Summary
A GraphQL service can be susceptible to N + 1 problem if not implemented correctly. The n+1 problem means that the GraphQL server executes many unnecessary round trips to fetch nested data. In Spring for GraphQL, we can solve this problem by defining a handler method with @BatchMapping annotation.








Discussion about this post