














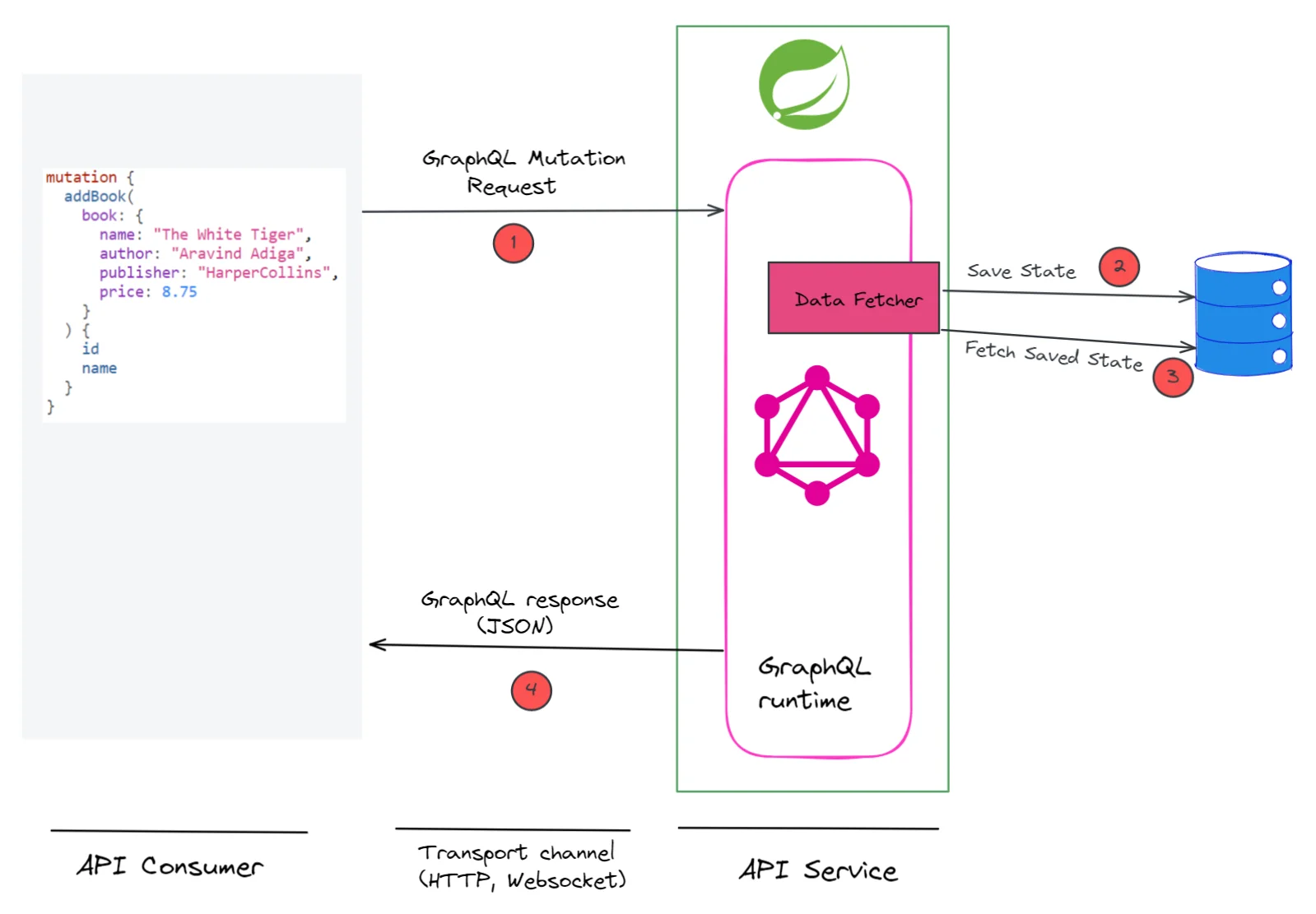
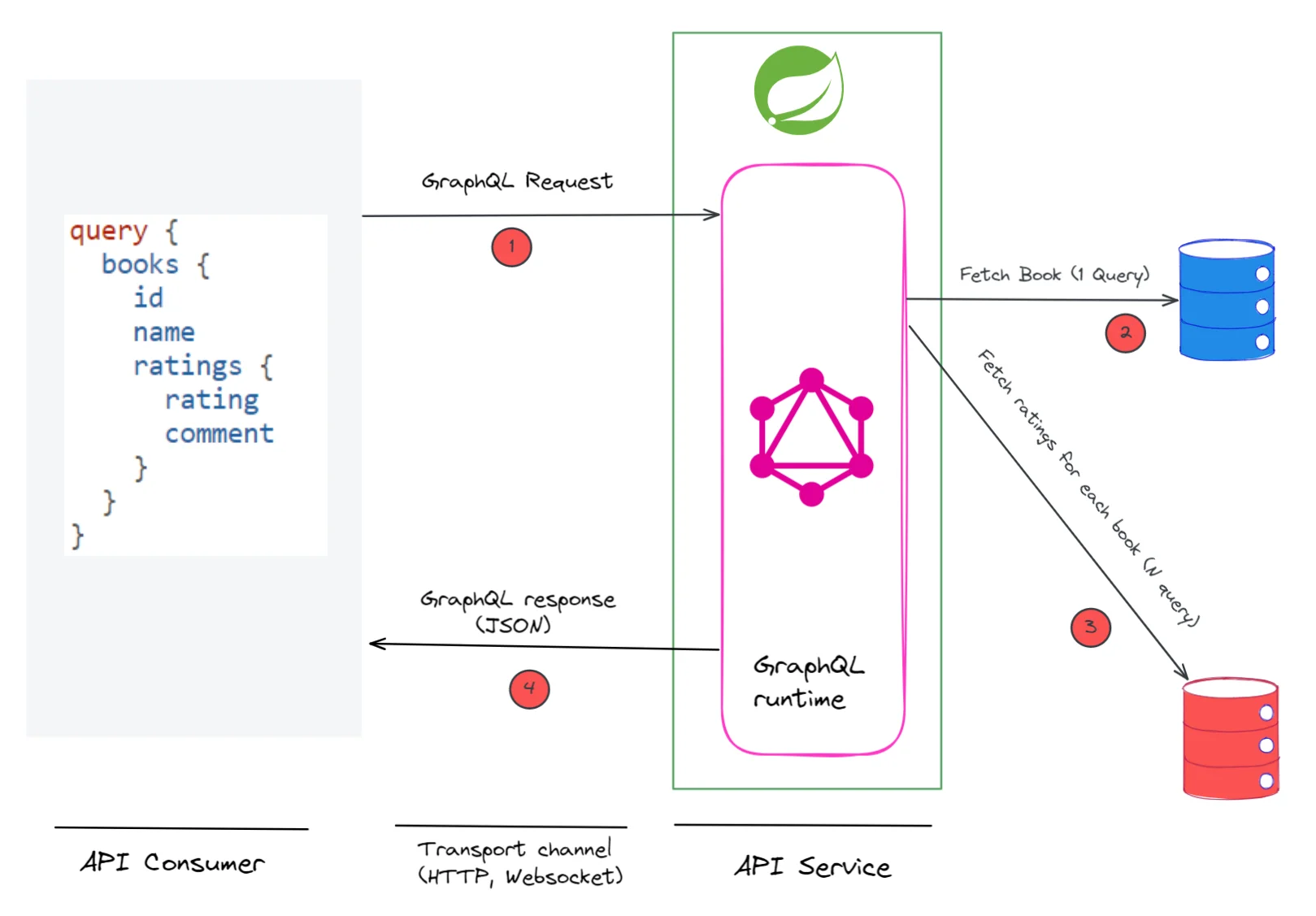









In 2012, I attended the JavaOne conference. In one of the talks, eBay engineers talked about how eBay was running 50,000 servers. They also mentioned that eBay was experimenting with a self-healing system to manage a fleet of 50,000 servers. This generated quite a buzz among the participants. Self-healing was quite a nascent concept those days. But not anymore. You don’t need to understand complex system concepts to build a self-healing system. You can use Kubernetes instead.
What is Kubernetes?
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications.It groups containers that make up an application into logical units for easy management and discovery.
The name Kubernetes originates from Greek, meaning helmsman or pilot. K8s as an abbreviation results from counting the eight letters between the “K” and the “s”. Google open-sourced the Kubernetes project in 2014. Kubernetes combines over 15 years of Google’s experience running production workloads at scale with best-of-breed ideas and practices from the community
https://kubernetes.io/
In recent times Kubernetes has become a de facto standard for deploying the containerized application in public, private, or hybrid cloud infrastructure. Kubernetes is an open-source container orchestration platform. Some of the important features provided by Kubernetes are –
- Automated rollouts and rollbacks
- Service discovery
- Self-healing
- Horizontal scaling
Let’s try to understand Kubernetes architecture and its main components.
Kubernetes Architecture
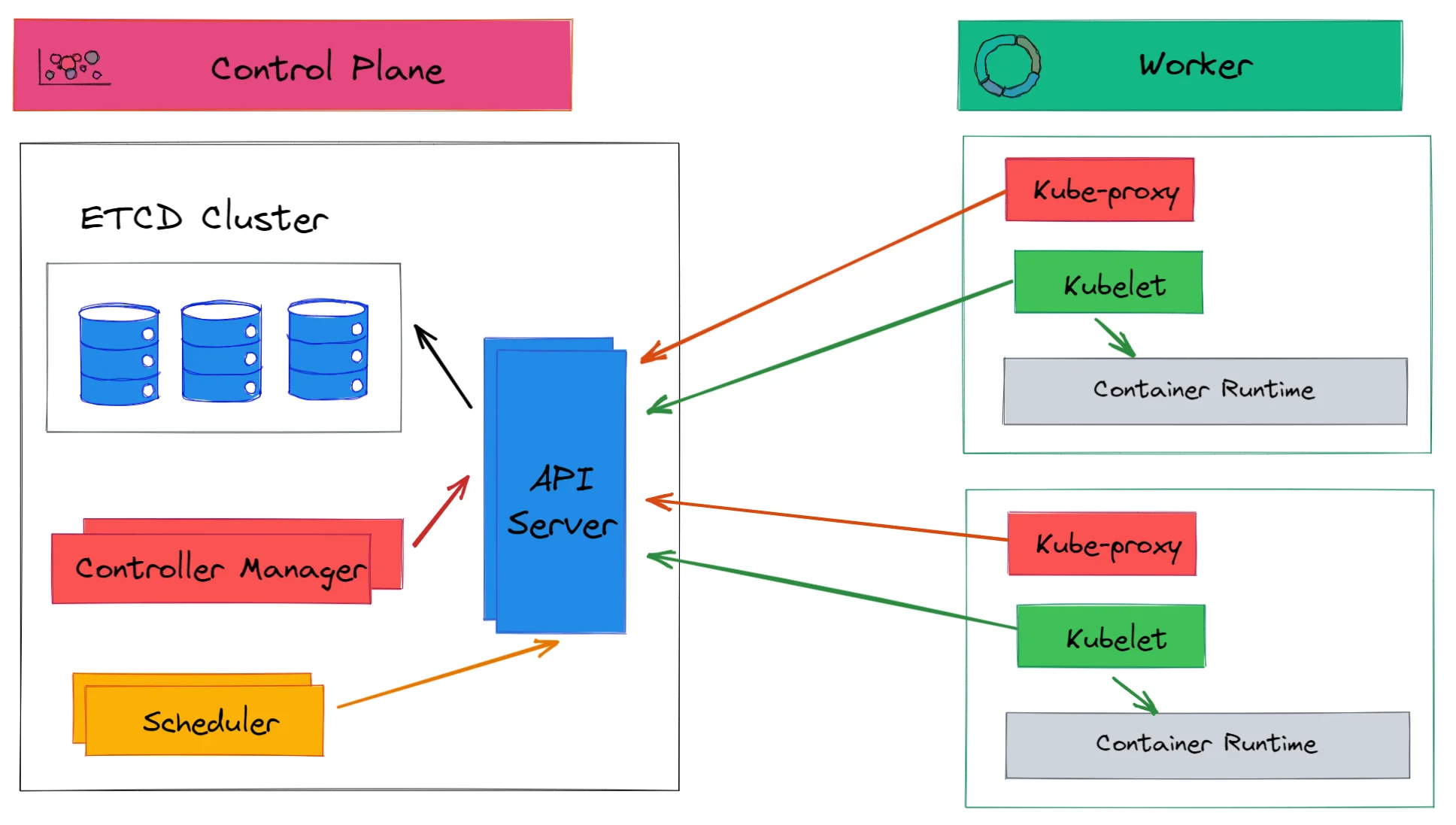
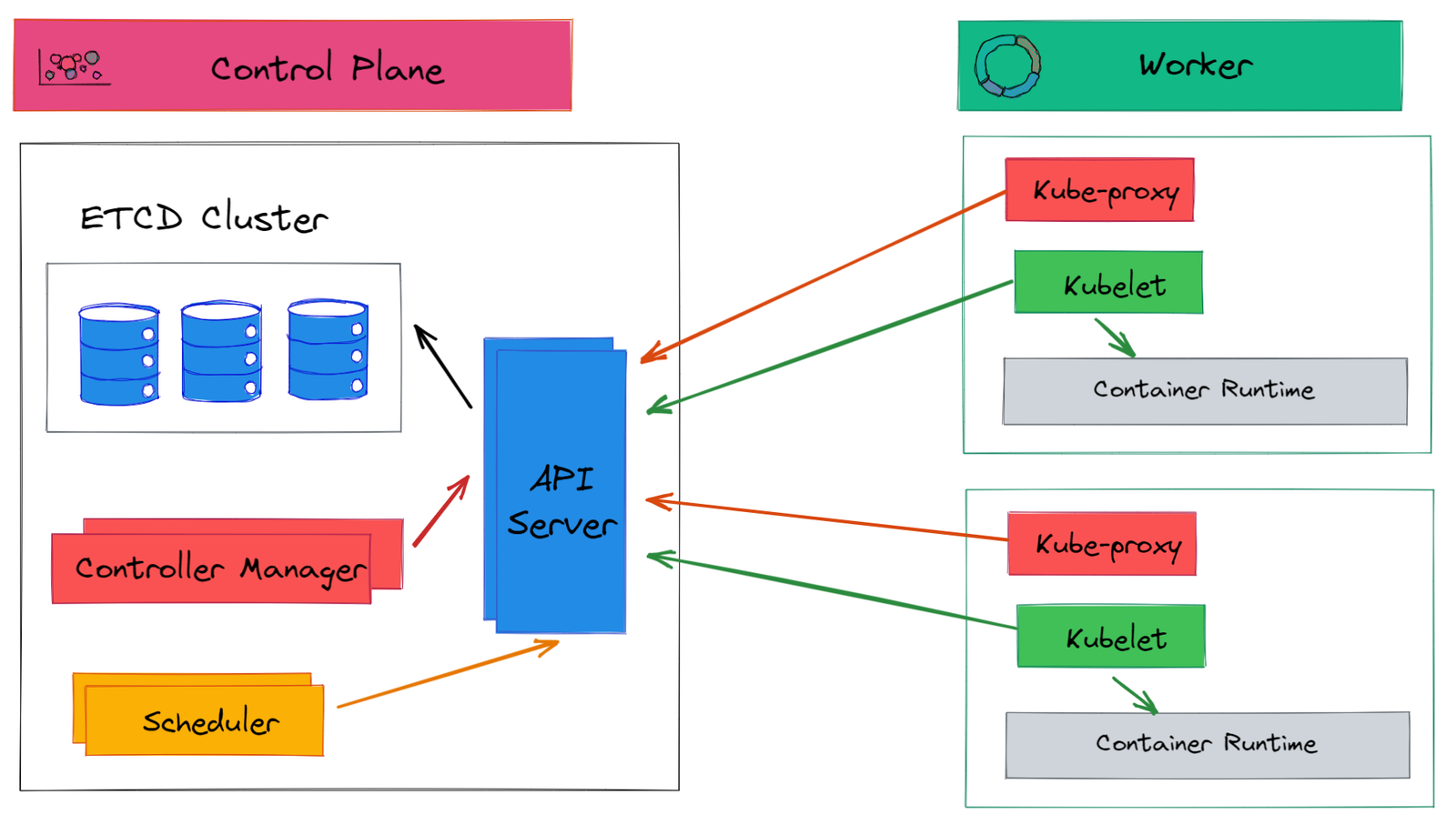
Kubernetes groups fleets of machines in a logical unit called the Kubernetes cluster. A Kubernetes cluster consists of the control plane and a set of worker machines, called nodes. You can run many control plane components in high availability mode.
Control plane
The control plane exposes the APIs to define, deploy and manage the lifecycle of containers. The control plane is made of many logical units. The control plane components are responsible for managing Kubernetes infrastructure.
Worker Nodes
The worker node(s) run the containerized applications. In Kubernetes, application workloads are called pods. Pods are hosted by the worker node(s). The control plane manages the worker nodes and the pods in the cluster.
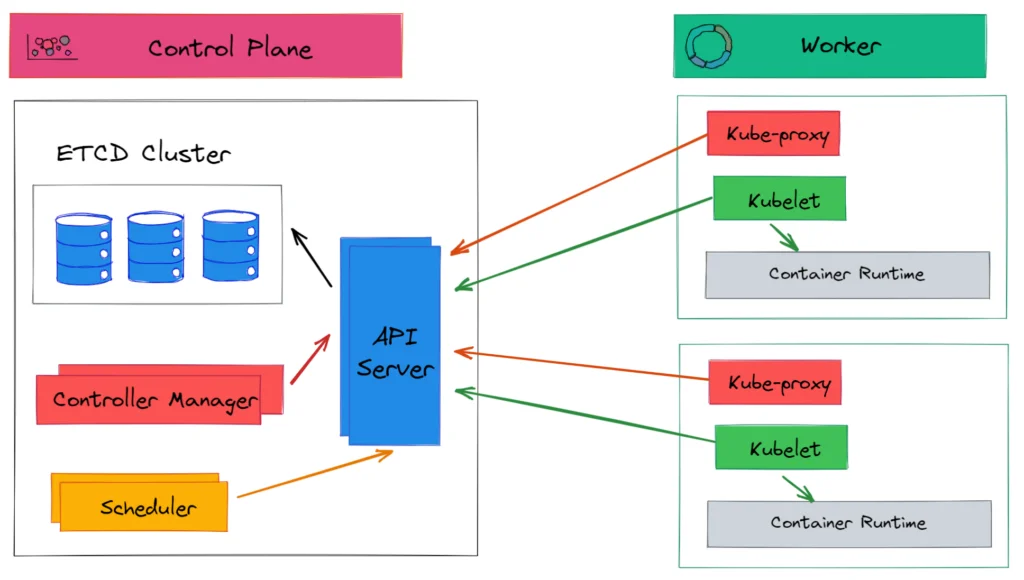
Control Plane components
The Kubernetes groups together fleets of machines in single logical units that can be managed by API. The control plane components are responsible for managing the Kubernetes infrastructure. A control plane is made of many logical components. Let’s see the control plane components.
API Server
The API Server is the main entry point to the Kubernetes cluster. It exposes a set of Kubernetes APIs that can be accessed by users and other components. The API server implements RESTful APIs over HTTP. The API server is stateless and can be scaled horizontally. The API servers stores state in the etcd store.
Kubernetes components only communicate with API Server. They don’t talk to each other directly. As shown in the above diagram, connections between API Server and other components are always established by components.
How client communicates with API Server?
When you create a Kubernetes resource using kubectl (or by directly calling API) then the API server performs many operations (as shown below).
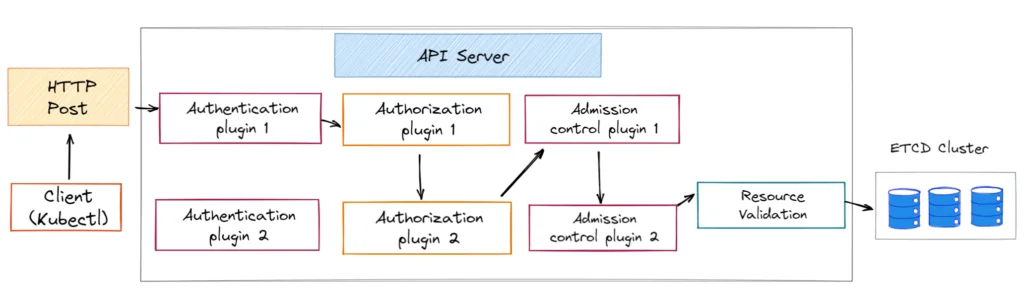
Authentication plugins
First, the API server authenticates the request using one of many authentication plugins. Kubernetes supports several authentication methods using an authentication plugin. Some examples of authentication methods are – X.509 client certificates, static HTTP bearer tokens, and OpenID Connect. Each authentication plugin implements a specific authentication method.
An incoming request is processed by each authentication plugin in sequence. If any of the authentication plugins can successfully verify the credentials in the request, then authentication is complete. And the request proceeds to the authorization stage.
Authorization plugins
After a request is authenticated, the API server does an authorization check using one of many authorization plugins/modules. Authorization plugin responsibility is to validate if the authenticated users can perform the requested action on the requested resource. If many authorization plugins are configured, then each is validated in sequence. Each authorization plugin can approve or deny a request and the result is returned immediately (short-circuit operation).
Admission Controller
Admission controller plugin intercepts requests (create, modify or delete) before persisting requests into etcd. The admission controller can mutate or validate the request. Mutating admission control may initialize missing fields, configure the default value or even override fields. The validating admission controller can reject a request.
ETCD
Kubernetes stores all cluster data in etcd. ETCD is a distributed, reliable, fast key-value store. You can run more than one instance of etcd to provide high availability and better performance.
In high availability mode, the etcd cluster implements a distributed consensus algorithm (RAFT). This ensures that even if one of the replicas failed then other replicas are available to serve requests reliably.
ETCD stores all cluster data. The ETDC cluster implements a distributed consensus algorithm (Raft) to ensure that even if one of the replicas failed then there are other replicas available to serve requests reliably.
Two other important services provided by etcd server are:
- Optimistic Locking: every value stored in etcd has a resource version. Any key-value written to etcd can be conditionalized against a resource version.
- Watch Protocol: etcd server implements watch protocol which enables the client to watch for changes in the key-values store and react accordingly.
The Kubernetes API server is the only component that talks to etcd directly. It’s the API server that provides features like ‘optimistic locking’ and ‘watch protocol’ to the client.
How API Server notifies about resource change?
The responsibility of the API server is to authenticate, authorize, validate and persist requests. It doesn’t create any resource neither it takes any scheduling decision. API server enables controllers and schedulers to observe changes in deployed resources. A Kubernetes component can request API Server to be notified whenever any operation is performed on the resource. This enables the component to perform whatever task it needs.
Interested clients can watch for changes by opening an HTTP connection to the API Server. Through this connection, clients will receive a stream of modification through watched objects.

Scheduler
When you ask Kubernetes to create a pod, usually you don’t tell which node pod should run. This task is done by the Scheduler. The Kube scheduler watches for newly created pods, which are not assigned to any node, and selects a node for them to run on.
When a pod is first created it usually doesn’t have a nodeName field. The nodeName field indicates the node on which pod to run. The Scheduler then selects the appropriate node for the pod and updates the pod definition with nodeName. After the nodeName is set the kubelet running on the node is notified which begins to execute the pod on that node.
Many factors influence how the scheduler selects the nodes. Some are supplied by the user, such as taints and tolerance, node affinity, etc. Some factors are determined by the scheduler. The selection of nodes for pods to run is a 2-step process:
Filtering
The filtering steps find the feasibility of nodes where the scheduler can schedule the pods. The filtering step is configured by predicates. The predicates are hard constraints, which, if violated, leads to the pod not operating correctly on that node. For example, the node-selector specified on the pod is a hard constraint.
Some of the pre-configured predicate functions that the scheduler can apply are :
- Can the node fulfil the harware resources needed by the pod?
- Does the node have a label that matches the node selector in the pod specification?
- Does the pod tolerate the taints of the node?
- Does node satisfy pod affinity or anti-affinity rules?
- Is the node running out of resources?
Scoring
After applying the filtering step, the scheduler ranks the available nodes based on priority functions. The scheduler assigns a score to each node based on the priority functions. The scheduler then assigns the pod to the node with the highest ranking. If there is more than one node with equal scores, the scheduler selects one of these at random.
One example of a priority function is the spreading function. This function prioritizes nodes such that all pods associated with a Kubernetes service are not present on one node. This ensures reliability since it reduces the chances that a machine failure will disable all endpoints associated with a particular Kubernetes service.
Controller Manager
In Kubernetes, Controllers are a control plane component that watches the current state of the Kubernetes cluster and tries to move the current state closer to to the desired state. The controller runs a control loop (a non-terminating loop that regulates the state of a system) which tracks at least one Kubernetes resource type and sends a message to the API server if the current state does not match the desired state.
Controllers never talk to each other directly. They don’t even know any other controllers exist. Controllers watch for changes to resources (Deployments, Services, and so on) and perform operations for each change. This operation could be a creation of a new object or an update or deletion of an existing object.
Some of the important controllers included in Kubernetes are:
- Replication Manager: responsible for ensuring desired number (replica count) of pods are running.
- DaemonSet Controller: creates, manages, and deletes DaemonSet resource by posting DaemonSet definition to the API server.
- Job Controller: creates, manages, and deletes Job resources by posting Job definitions to the API server.
- StatefulSet Controller: creates, manages, and deletes pods according to the spec of a StatefulSet resource
- Node Controller: manages the worker node resources.
Node Components
In addition to the components that run on the master node (control plane), few components run on every worker node. These components provide an essential feature that is required on all nodes.
Kubelet
The Kubelet is the node agent that runs on all machines that are part of a Kubernetes cluster. It is responsible for everything running on a worker node. It registers the node it’s running on by creating the Node resource in the API server. The Kubelet acts as a bridge that joins the available CPU, disk, and memory for a node into the large Kubernetes cluster.
The Kubelet communicates with the API server to find containers that should be running on its node. The Kubelet also communicates the state of the containers to the API server so that the controller can observe the current state of these containers.
The Kubelet is also responsible for the health check on the machines. If a container is run by the Kubelet dies or fails its health check, the Kubelet restarts it, while also communicating this health state and the restart to the API server. it terminates containers when the pod is deleted from the API server and notifies the server that the pod has terminated.
Kube Proxy
The Kubernetes service is the way to expose an application running on a set of pods as a network service. Kubernetes assigns a single DNS name for a set of pods and load-balances the requests against them. The kube-proxy purpose is to make sure clients can connect to the Kubernetes service. It is responsible for implementing the Kubernetes Service load-balancer networking model.
The kube-proxy is always watching the API server for all services in the Kubernetes cluster. When a Kubernetes service is created it’s immediately assigned a virtual IP address i.e. it’s not assigned to any network interface. The API server then notifies all kube-proxy agents about the new service. The kube-proxy sets up a few iptables rules to redirect client calls to a service to the backing pod.
Container run time
The container runtime is the software that is responsible for running containers. Kubernetes supports several container runtimes: Docker, containerd, CRI-O, and any implementation of the Kubernetes CRI (Container Runtime Interface).
Summary
A Kubernetes cluster consists of the control plane and a set of worker machines, called nodes. The control plane is responsible for managing Kubernetes infrastructure. The control plane component includes:
- API Server: API Server is the main entry point to the Kubernetes cluster. It exposes a set of Kubernetes APIs that can be accessed by users and other components.
- etcd: etcd is a distributed, reliable, fast key-value store. Kubernetes stores all cluster data in etcd.
- Scheduler: the scheduler is responsible for scheduling a pod.
- Controller: controllers are responsible for maintaining the current state of the cluster closer to to the desired state.
Components that run on the worker nodes are:
- Kubelete: kubelet is an agent that runs on all worker nodes and is responsible for running containers.
- Kube Proxy: kube-proxy is responsible for service discovery and managing Kubernetes internal networking.
- Container run time: container runtime is responsible for running containers.
Further Reading
- Kubernetes documentation
- Book – Kubernetes in Action by Marko Lukša





Discussion about this post