














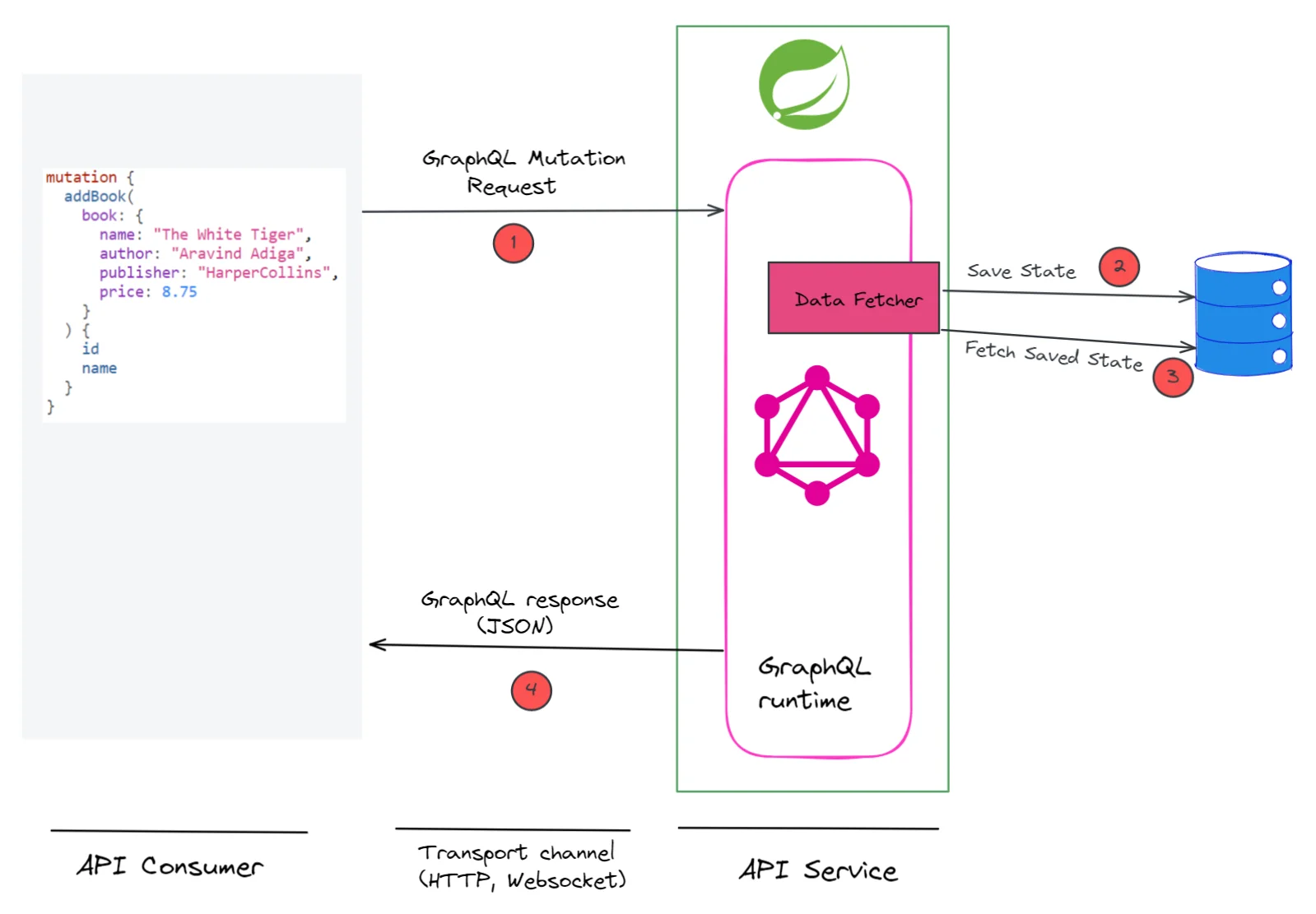
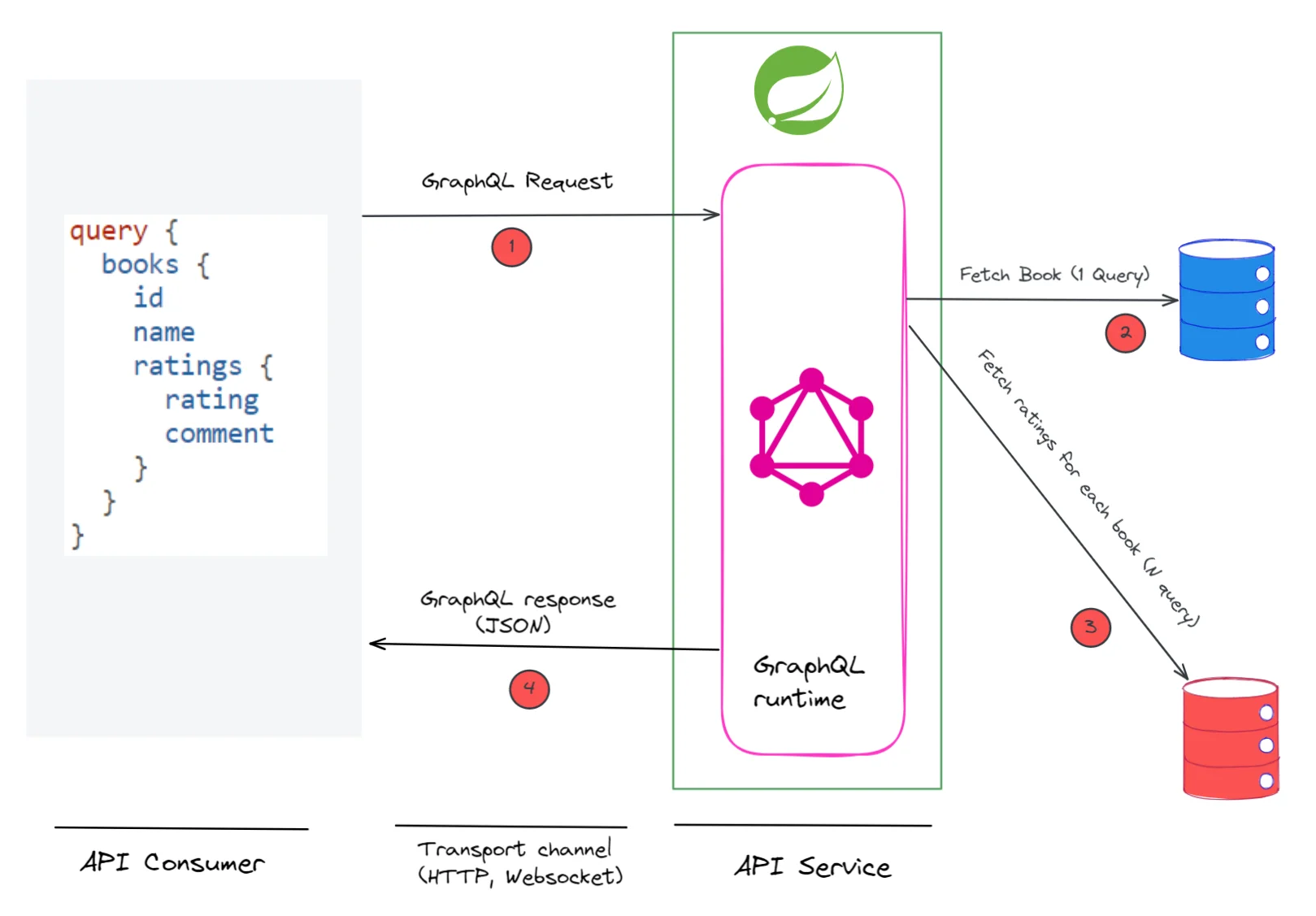










.
Pagination is a key concept for managing data requests in GraphQL and other web APIs. By breaking up the data into smaller, more manageable chunks, pagination ensures that GraphQL API requests are optimized for efficiency. It also ensures that we are not simultaneously overloading our services with too much data. Pagination enhances the user experience by breaking down content into bite-sized portions, making navigating the data easier.
In this article, we will see how to implement pagination in Spring for GraphQL with code examples. During the process, we will understand the key concept of pagination and different pagination technique, namely cursor-based vs offset-based
If you’re interested in learning more about GraphQL, be sure to check out our other posts.
Pagination Approach
There are two popular approaches to implementing pagination: offset-based and Cursor-based.
Offset-Based Pagination
Offset-based pagination is a simpler and more traditional approach to pagination. It relies on specifying the number of items to fetch and the dataset’s starting position (offset).
How it works:
- The client specifies the number of items to fetch (the limit) and the dataset’s starting position (the offset).
- The server returns a slice of the dataset, starting from the specified offset and containing the requested items.
- To fetch subsequent pages, the client increments the offset and requests the next slice of items.
In a REST API, the offset-based pagination can look like:
GET /items?limit=20&offset=100
And in GraphQL:
query items {
items(limit: 20, offset : 100) {
...
}
}
The biggest advantage of offset-based pagination is Simplicity; it’s straightforward to implement and understand, making it a popular choice for smaller datasets or simple use cases.
Some disadvantages to offset-based pagination are:
- Stability: Offset-based pagination may be less stable when items are added to or removed from the dataset. If items are inserted or deleted between pagination requests, subsequent pages may contain duplicate or missing data.
- Performance Impact: As the offset increases, fetching subsequent pages becomes slower. The database might need to scan and skip many records for large offsets, negatively impacting performance.
Despite its shortcomings, offset-based pagination is still a popular choice (Spotify’s REST API) for implementing pagination if the queried list doesn’t change frequently.
Cursor-Based Pagination
Cursor-based pagination, also known as keyset pagination, is a technique that uses a unique identifier or cursor to paginate through a dataset. Rather than relying on offsets or page numbers, cursor-based pagination provides a more reliable and efficient way to navigate data.
How it works:
- Each item in the dataset is assigned a unique identifier as a cursor. This identifier must be a sortable attribute such as a primary key, timestamp, etc.
- The client initially requests a specific number of items. In response, the server includes a cursor of the last item and some other metadata (which we’ll see shortly).
- To fetch the next page, the client includes the cursor of the last item received in the previous request as an argument in the subsequent query. This allows the server to determine the position in the dataset and return the next set of items after the specified cursor.
- The server returns the requested items and their corresponding cursors for the client to use in subsequent queries.
Advantages:
- Stability: Cursor-based pagination remains stable even if new items are added or removed from the dataset. Since it relies on unique identifiers, the pagination results are consistent regardless of changes to the dataset.
- Efficient Navigation: Cursor-based pagination allows users to navigate back and forth through pages easily. They can directly jump to a specific position in the dataset by specifying the cursor of the desired item.
- Performance: As cursor-based pagination does not rely on offsets, it eliminates the need for expensive operations like skipping a specific number of items. This can result in better performance, especially when dealing with large datasets.
In a REST API, the cursor-based pagination can look like:
//Initial Request
GET /items?limit=20
//Subsequent request
GET /items?limit=20&after_id=ABC345
In GraphQL:
#Initial Request
query items {
items(first: 20) {
...
}
}
#Subsequent request
query items {
items(first: 20, after : "ABC345") {
...
}
}
GraphQL Pagination
The most common pagination approach in GraphQL comes from Relay’s GraphQL Cursor Connections Specification, which has become the de facto standard for handling large lists in GraphQL schemas. Relay is a JavaScript framework for fetching GraphQL in React applications.
The Relay Connections Specification utilizes cursor-based pagination. As previously explained, the cursor identifies the position within the list where we start a slice, and then we select another cursor and slice again. We can slice backward or forward but not skip elements; we must request a fresh slice relative to a cursor.
If we need to implement pagination of Book collection based on Relay connection specification, we can write GraphQL schema as:
type Query {
books (first: Int, after: String, last: Int, before: String): BookConnection
}
type BookConnection {
edges: [BookEdge]
pageInfo: BookInfo!
}
type BookEdge {
cursor: String
node: Book!
}
type BookInfo {
startCursor: String
endCursor: String
hasNextPage: Boolean!
hasPreviousPage: Boolean!
}
type Book {
id : ID
name : String
author: String
price: Float
}
The Relay connections specification involves few key concepts such as Connections, Edges, Nodes, and PageInfo. Let’s take a closer look at each one.
Let’s take a closer look at the schema mentioned above.
Query
The books (first: Int, after: String, last: Int, before: String) query enables the pagination of the book collection in both forward and backward directions. For instance, a client can request the first 20 books as follows:
query Books {
books(first: 20) {
#Other fields
}
}
Afterward, the client can request the next 20 books as:
query Books {
books(first: 20, after : "MTAwMQ==") {
#Other fields
}
}
Where “MTAwMQ==” is the cursor returned by the first request. The cursor value is usually Base64 encoded.
Why encode cursor?
Cursors are Base64 encoded to make them compact and hide implementation details. This approach also discourages clients from making assumptions about the field and allows the server to encode additional information within the cursor.
Similarly, a client can navigate backward by requesting the last 20 items before the cursor as:
query Books {
books(last: 20, before : "MTAwMQ==") {
#Other fields
}
}
Connection
A connection represents a page of data (edges) and additional metadata (pageInfo) that enables clients to request more pages.
The Connection type must have at least the two fields edges and pageInfo.
type BookConnection {
edges: [BookEdge]
pageInfo: BookInfo!
}
An edge is a wrapper containing the data and additional metadata. Pagination metadata is always called PageInfo and shared across all edges.
Edges
The edges of a connection represent pages of data (items requested by the client, for example, books(first: 20) will have 20 edge). An edge is a wrapper object that contains a data element, such as a Book and metadata. It must have at least two fields: the cursor for the current element and the actual element named node.
type BookEdge {
cursor: String
node: Book!
}
PageInfo
The PageInfo type contains pagination metadata that summarizes a query’s requested edges. It must contain the following fields:
type BookInfo {
startCursor: String
endCursor: String
hasNextPage: Boolean!
hasPreviousPage: Boolean!
}
Request and Response Example
A client can request the first 20 pages as:
query books {
books(first: 20) {
edges {
cursor
node {
id
name
author
price
}
}
pageInfo {
startCursor
endCursor
hasNextPage
hasPreviousPage
}
}
}
And the server will return a response like:
{
"data": {
"books": {
"edges": [
{
"cursor": "MTAwMQ==",
"node": {
"id": "1001",
"name": "The Great Gatsby",
"author": "F. Scott Fitzgerald",
"price": 9.99
}
},
{
"cursor": "MTAwMg==",
"node": {
"id": "1002",
"name": "To Kill a Mockingbird",
"author": "Harper Lee",
"price": 12.49
}
},
......
{
"cursor": "MTAyMA==",
"node": {
"id": "1020",
"name": "A Tale of Two Cities",
"author": "Charles Dickens",
"price": 9.99
}
}
],
"pageInfo": {
"startCursor": "MTAwMQ==",
"endCursor": "MTAyMA==",
"hasNextPage": true,
"hasPreviousPage": false
}
}
}
}
The client can further request the next 20 pages as :
query moreBooks {
books(first: 20, after: "MTAyMA==") {
edges {
cursor
node {
id
name
author
price
}
}
pageInfo {
startCursor
endCursor
hasNextPage
hasPreviousPage
}
}
}Where MTAyMA== is the cursor returned in the first request.
The server response:
{
"data": {
"books": {
"edges": [
{
"cursor": "MTAyMQ==",
"node": {
"id": "1021",
"name": "The Little Prince",
"author": "Antoine de Saint-Exupéry",
"price": 7.99
}
},
{
"cursor": "MTAyMg==",
"node": {
"id": "1022",
"name": "The Hunger Games",
"author": "Suzanne Collins",
"price": 11.99
}
},
.......
{
"cursor": "MTA0MA==",
"node": {
"id": "1040",
"name": "The Adventures of Huckleberry Finn",
"author": "Mark Twain",
"price": 10.99
}
}
],
"pageInfo": {
"startCursor": "MTAyMQ==",
"endCursor": "MTA0MA==",
"hasNextPage": true,
"hasPreviousPage": true
}
}
}
}The client can paginate backward by requesting the last 20 items as:
query books {
books(last: 20, before: "MTAyMQ==") {
edges {
cursor
node {
id
name
author
price
}
}
pageInfo {
startCursor
endCursor
hasNextPage
hasPreviousPage
}
}
}Server response:
{
"data": {
"books": {
"edges": [
{
"cursor": "MTAwMQ==",
"node": {
"id": "1001",
"name": "The Great Gatsby",
"author": "F. Scott Fitzgerald",
"price": 9.99
}
},
{
"cursor": "MTAwMg==",
"node": {
"id": "1002",
"name": "To Kill a Mockingbird",
"author": "Harper Lee",
"price": 12.49
}
},
.......
{
"cursor": "MTAyMA==",
"node": {
"id": "1020",
"name": "A Tale of Two Cities",
"author": "Charles Dickens",
"price": 9.99
}
}
],
"pageInfo": {
"startCursor": "MTAwMQ==",
"endCursor": "MTAyMA==",
"hasNextPage": true,
"hasPreviousPage": false
}
}
}
}Spring for GraphQL Implementation
Before we jump into GraphQL implementation, let’s understand how to fetch data for pagination. We will use RDBMS in this example, but the approach can be similar to any other database.
Get First n Items
When a client requests the first 20 elements as books(first: 20), the SQL query looks like this:
SELECT id,name, author, price,
false AS has_page
FROM book
ORDER BY ID LIMIT n + 1In the above query, we sort data by ID and specify the limit as count plus one to fetch one more result than the client specified. This is useful for determining the value of hasNextPage.
As this is the first request false AS has_page implies that hasPreviousPage is false.
Get Next n Items
The client can request the next n items as books(first: 20, after: "MTAyMA==")where "MTAyMA=="is the cursor obtained in the first request.
In this case, the SQL clause EXISTS (SELECT 1 FROM book WHERE id < cursor) AS has_page tells us if there is a hasPreviousPage, and we get the next n items from the cursor as WHERE id > cursor .
Also, LIMIT is set to n + 1 to determine if there are more pages (hasNextPage).
SELECT id,name, author, price,
EXISTS (SELECT 1 FROM book WHERE id < cursor) AS has_page
FROM book
WHERE id > cursor
ORDER BY id
LIMIT n + 1Get Previous n Items
The cursor-based pagination allows a client to request data in both forward and backward directions. A client can request previous items as books(last: 10, before: "MTEwMA==").
To get the previous n items, we use WHERE id < cursor and clause EXISTS (SELECT 1 FROM book WHERE id > cursor) AS has_page tells us if there is a next page.
Also, LIMIT is set to n + 1 to determine if there are more pages (hasPreviousPage).
SELECT id,name, author, price,
EXISTS (SELECT 1 FROM book WHERE id > cursor) AS has_page
FROM book
WHERE id < cursor
ORDER BY id
LIMIT n + 1
Controller Implementation
Like any GraphQL implementation, we declare @QueryMapping() to map GraphQL request to the controller method as:
@QueryMapping()
public BookConnection books(
@Argument("first") Integer first,
@Argument("after") String after,
@Argument("last") Integer last,
@Argument("before") String before) {
return bookCatalogService.getBookConnection(new CursorInfo(first, after, last, before));
}
In the above code, the controller delegates the fetching of paginated data to the service bookCatalogService.
Service Implementation
When a client requests the next n items by passing the cursor, we set the limit as var limit = pageSize + 1 to get one extra item, and comparison hasNextPage = resultSize > pageSize tells us if there is a next page. The hasPreviousPage is determined by the result of SQL Clause EXISTS (SELECT 1 FROM book WHERE id < cursor) AS has_page as hasPreviousPage = firstResult.hasPage(). The endCursor is determined based on the result set size; if the result set size is more than the page size, then we take pageSize - 1 as the index; else resultSize - 1.
int pageSize = cursorInfo.pageSize();
// Limit is pageSize + 1
var limit = pageSize + 1;
// ...
if (cursorInfo.hasCursors() && cursorInfo.hasNextPageCursor()) {
bookResults =
bookRepository.booksWithNextPageCursor(CursorInfo.decode(cursorInfo.getCursor()), limit);
int resultSize = bookResults.size();
var firstResult = bookResults.get(0);
hasPreviousPage = firstResult.hasPage();
startCursor = CursorInfo.encode(firstResult.id());
int endCursorIndex = resultSize > pageSize ? pageSize - 1 : resultSize - 1;
endCursor = CursorInfo.encode(bookResults.get(endCursorIndex).id());
hasNextPage = resultSize > pageSize;
} else if (cursorInfo.hasCursors() && cursorInfo.hasPrevPageCursor()) {
Similarly, for backward pagination, the comparison hasPreviousPage = resultSize > pageSize tells us if there is a previous page, and hasNextPage is determined by SQL clause EXISTS (SELECT 1 FROM book WHERE id > cursor) AS has_page.
} else if (cursorInfo.hasCursors() && cursorInfo.hasPrevPageCursor()) {
bookResults =
bookRepository.booksWithPreviousPageCursor(
CursorInfo.decode(cursorInfo.getCursor()), limit);
int resultSize = bookResults.size();
var firstResult = bookResults.get(0);
hasNextPage = firstResult.hasPage();
startCursor = CursorInfo.encode(firstResult.id());
int endCursorIndex = resultSize > pageSize ? pageSize - 1 : resultSize - 1;
endCursor = CursorInfo.encode(bookResults.get(endCursorIndex).id());
hasPreviousPage = resultSize > pageSize;
} else {
Getting the first n items, as books(first: 20), is similar to the earlier implementation described above.
} else {
bookResults = bookRepository.booksWithoutCursor(limit);
int resultSize = bookResults.size();
hasPreviousPage = false;
var firstResult = bookResults.get(0);
startCursor = CursorInfo.encode(firstResult.id());
int endCursorIndex = resultSize > pageSize ? pageSize - 1 : resultSize - 1;
endCursor = CursorInfo.encode(bookResults.get(endCursorIndex).id());
hasNextPage = resultSize > pageSize;
}
You can find the full implementation of BookCatalogService in the GitHub repo.
Repository Implementation
We have used Spring JPA for our repository layer as
@Repository
public interface BookRepository extends JpaRepository<BookEntity, Integer> {
@Query(nativeQuery = true)
List<BookResult> booksWithNextPageCursor(Integer id, int limit);
@Query(nativeQuery = true)
List<BookResult> booksWithPreviousPageCursor(Integer id, int limit);
@Query(nativeQuery = true)
List<BookResult> booksWithoutCursor(int limit);
}
And to map the result of the native query to the BookResult object, we have used @NamedNativeQuery and resultSetMapping as:
@NamedNativeQuery(
name = "BookEntity.booksWithNextPageCursor",
query =
"""
SELECT id,name, author, price,
EXISTS (SELECT 1 FROM book WHERE id < ?1) AS has_page
FROM book
WHERE id > ?1
ORDER BY id
LIMIT ?2
""",
resultSetMapping = "Mapping.BookResult")
@NamedNativeQuery(
name = "BookEntity.booksWithPreviousPageCursor",
query =
"""
SELECT id,name, author, price,
EXISTS (SELECT 1 FROM book WHERE id > ?1) AS has_page
FROM book
WHERE id < ?1
ORDER BY id
LIMIT ?2
""",
resultSetMapping = "Mapping.BookResult")
@NamedNativeQuery(
name = "BookEntity.booksWithoutCursor",
query =
"""
SELECT id,name, author, price,
false AS has_page
FROM book
ORDER BY ID LIMIT ?1
""",
resultSetMapping = "Mapping.BookResult")
@SqlResultSetMapping(
name = "Mapping.BookResult",
classes =
@ConstructorResult(
targetClass = BookResult.class,
columns = {
@ColumnResult(name = "id"),
@ColumnResult(name = "name"),
@ColumnResult(name = "author"),
@ColumnResult(name = "price"),
@ColumnResult(name = "has_page")
}))
@Entity
@Table(name = "book")
public class BookEntity {
@Id private Integer id;
private String name;
private String author;
private Double price;
}
Where repository method booksWithNextPageCursor is mapped to @NamedNativeQuery( name = "BookEntity.booksWithNextPageCursor", ..). I’ll not go into details of Spring JPA native query implementation. For that, you can check A Guide to SqlResultSetMapping.
Code Example
The working code example of this article is listed on GitHub. To run the example, clone the repository and import graphql-spring-pagination as a project in your favorite IDE as a Gradle project.
You can run the application from IDE, which starts GraphQL server on port 8080, and use GraphiQL to test the application.
Summary
In this article, we saw an overview of pagination in GraphQL. The Relay Connections Specification is the de facto standard for implementing pagination in GraphQL. This specification uses cursor-based pagination, which is more stable and performant than offset-based, allowing us to paginate in both directions.
The Relay Connections Specification relies on four key concepts: Connections, Edges, Nodes, and PageInfo. A connection represents a page of data (edges) and additional metadata (pageInfo) that enables clients to request more pages.








Discussion about this post